File Organization
• Files in BSDFS are organized in one category.
There is no hierarchy of directory in the system.
• Every file in the system has a unique name.
• Two consistent copies for one file:
1) For fault tolerance purpose, a file in the distributed file system
has at least 2 copies residing on 2 different file servers.
2) At least 2 copies for a file in the system should keep consistent
all the time. One of them is primary copy; others of them are backup
copies.
File Server
It is the container of the files in the distributed
file system.
Three roles of file servers
There are three types of file servers that are in charge of its maintenance
and operations:
• Primary file server: this server keeps the primary copy for
the file. At the same time, it is the control center for all the accesses
to the file.
• Backup file server: this server keeps a backup copy for the
file.
• Cache file server (Replica Server): for each file opened by
the client connected to it, the cache server establishes a replica of
the file locally for the client to access.
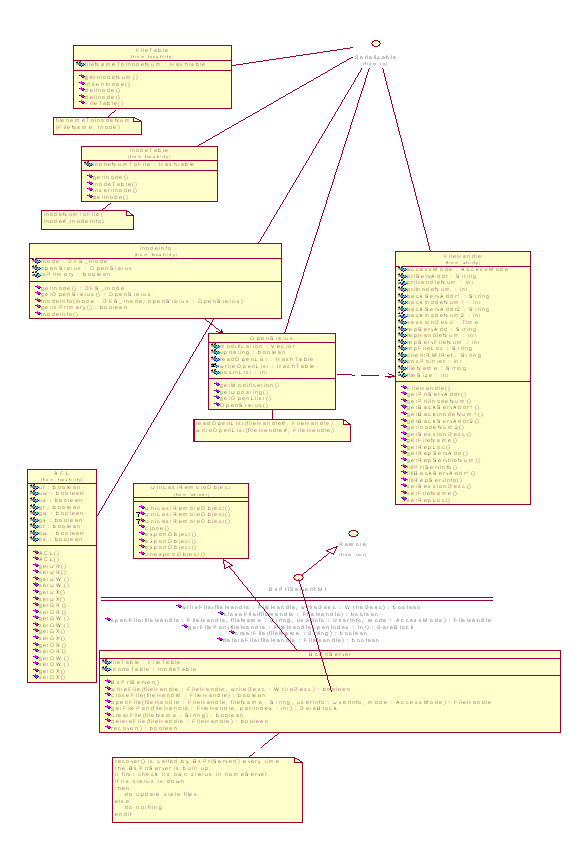
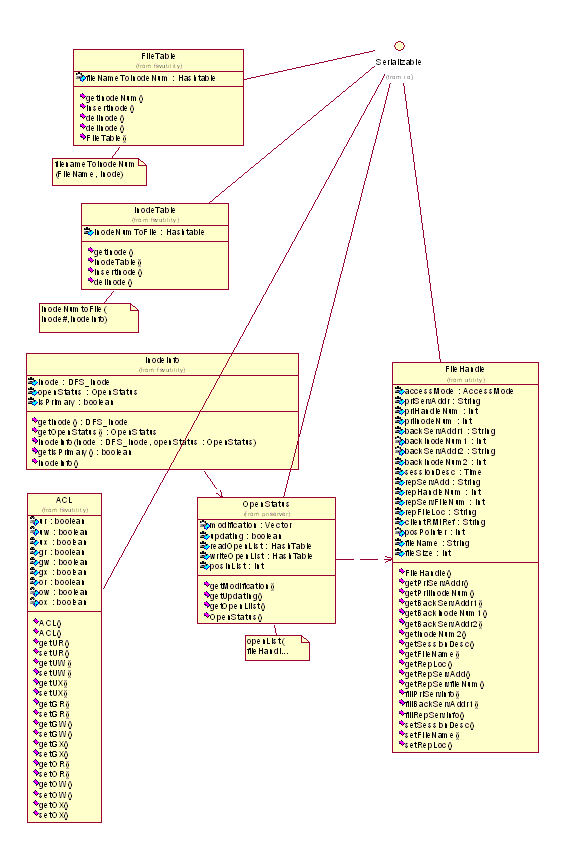
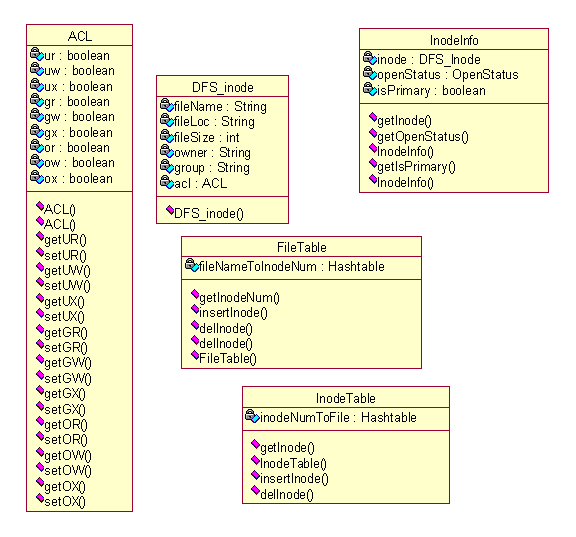
Dfs-inode
• The file server keeps information for files copies located on
it, which belongs to the distributed file system.
• The information includes: the file name, file’s location
on local file system, file’s owner, file access control information,
the number of consistent copies of the file, the number of the local
copy for the file, etc.
• Such information is kept in a data structure named as dfs-inode.
Access Session descriptor
• Once a file is opened, the primary server of the file will establish
an access session descriptor for the open of the file.
• This descriptor consists of the information for the access session,
including session ID, the file’s open time, the file’s lease
time(in basic version of the distributed file systems), file update
status, current permission to the handle, etc.
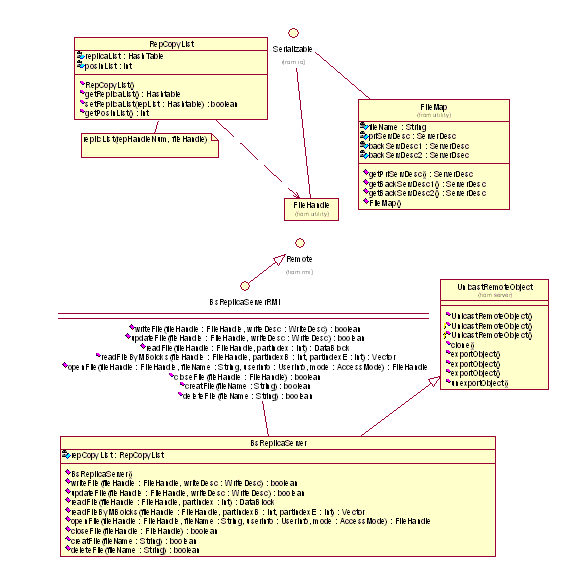
File handle
• Every open operation to a file causes a file handle to be created
for the file access session.
• The file handle consists of the dynamic information for an access
to the file in the whole process till the file is closed.
• The information in the handle consists of the file’s global
unique name, the addresses of file servers holding the file’s
copies, information of the dfs-inode, the ID of replica file on cache
server, the ID of the descriptor of the access session in primary server,
the type of object that holds the handle, etc.
Opened file list
• The primary server of a file keeps a list for all the opened
session for the file.
• The open list is a list of the file handles for opened file.
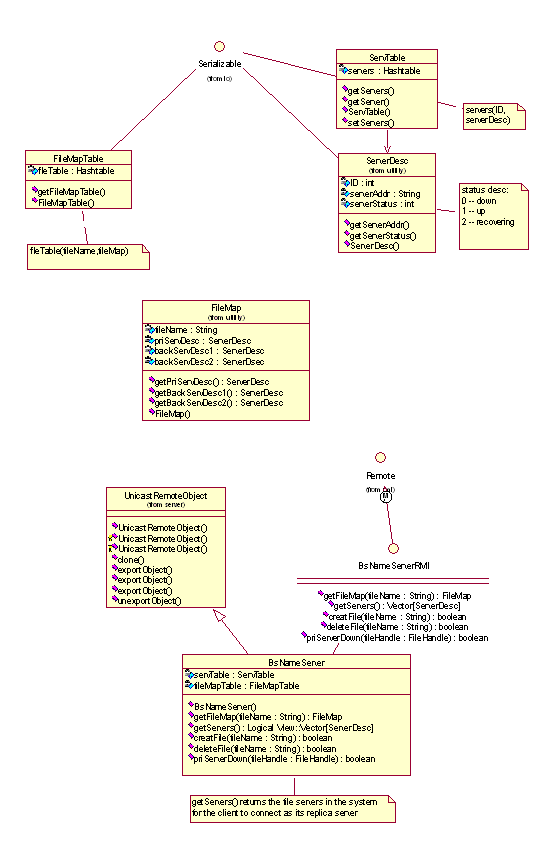
Name Server
There are 2 name servers in the system: the primary name
server and the backup name server
for the purpose of name server’s fault tolerance.
The Name Server has 2 main functions:
• Keep tracking of the servers in the system and record their
status, including their availability. Provide server discovery service;
provide the server information for fault tolerance purpose; maintain
the availability of the file system.
• Map the files in the distributed file system on to the servers
they reside on and provide the service for this mapping to the file
servers in the system.
Client
Customers use the client component to access the files in the system.
The client component is provided as an API. For each file it opens,
the client holds a file handle and has a cache for the file access.
The client keeps addresses of the name servers in the system, in order
to find out appropriate file server to connect to. In the client, some
information is kept for the opened files:
• Cache: cache the data read from the cache server.
• Opened file list: a list a file handle that indicates the files
opened on the client.
Mechanism
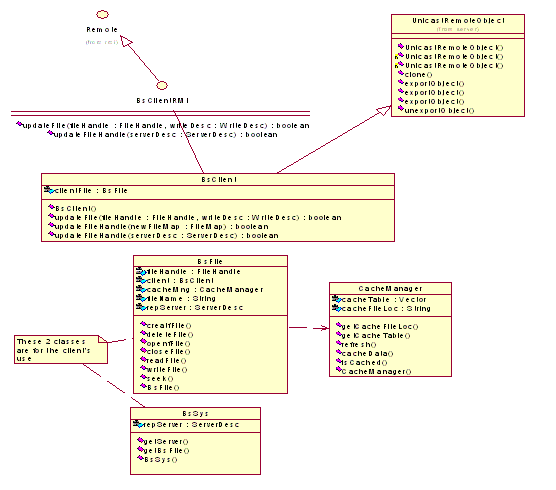
Client Cache
The cache in client is file cache. When a file is opened, the client
will created a cache file to cache the data it reads from the replica
server. The cache has a block size of 4k bytes. There is a cache table
used to maintain the cache file and the cache status. The cache manager
manages the client’s cache file. It’s the cache manager’s
responsibility to keep and update the status of the cache; when data
the client needs is not in the cache, it fetches the data through replica
server; when the file is updated in the file server, it refresh the
cache status of the cache file.
Write-through strategy: when write invoked
by the client, the data is tried to updated to the file in replica server,
which in turn try to write the data to the primary server and backup
server for the file; and is written into the replica copy of the file
and the cache file (if it is successfully written into the file in the
primary server).
Server-initiated update: the consistency of
cached data is maintained by updating from the primary server. Primary
server is the center controller for all access to a file. When a client
writes a file, the write operation goes through the primary server;
the primary server inform all the replicas for the file in the system
to do the update of the file; and the cache status for the corresponding
parts at the client is refreshed(If the corresponding data part is cached
in the cache file in client, the cache tag for those part would be set
to indicate that that part data is invalid in the cache.
Disconnection Operation
In order to provide the availability for the files and access to the
files in the system, the system supports 2 main types of disconnection
management.
Replica server disconnection - handle the disconnection
between the client and replica server
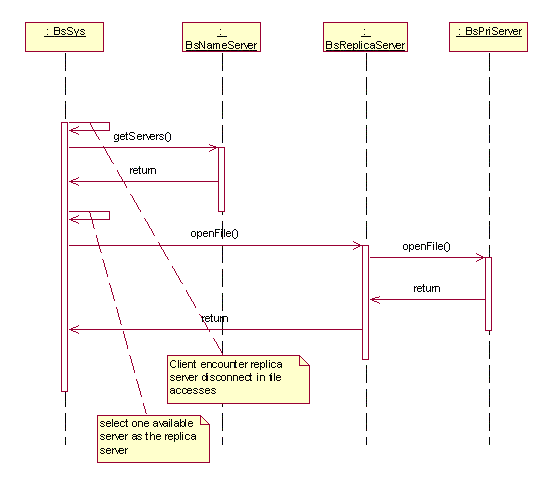
Before accessing any file in the system, the client need to connect
to the system, which means that the client find a replica server to
use it as an access gate to the files in the system. After the client
connected to a replica server, the replica server may become unavailable
at later time. In this case, the client will find the disconnection
in the following file operation; once it find the disconnection, the
client initiate a procedure to reconnect to the system – to find
another replica to connect. When a new replica server is found, a new
file replica is created on it for the client’s access. The mechanism
is shown in the following diagram.
Primary server disconnection - handlethe disconnection
between the replica server and primary server
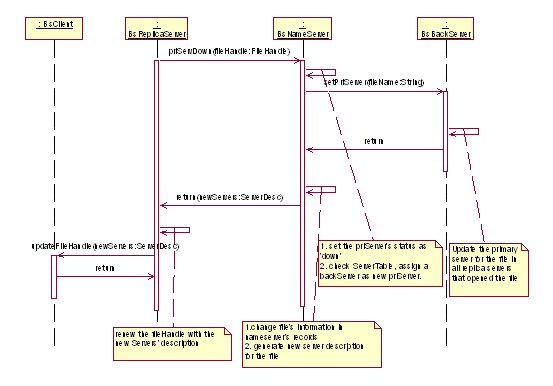
Primary server is the access control and service center for a file.
So its availability is very important.
Dynamic primary server assignment:
The availability of primary server service is implemented by the cooperation
of the primary server and backup server with dynamic primary server
assignment. In our system, when a replica server finds the file’s
primary server is down, it informs the name server about and requires
a re-assignment to a new primary server. The name server thus contacts
the backup server and requires it to change its role to primary server
if it is available. And then all clients that opened the file will be
informed of the change of the primary server for the file. Consequently,
the primary server is shift from one machine to the other. If the backup
server is unavailable either, the replica server will be informed that
the file on the server can not be access at this time, and the client
do the access of the file locally in the cache or on the replica copy
of the file, which do not throw the replicas out of synchronization.
The mechanism can be see from the following brief diagram.
Server Discovery Mechanism
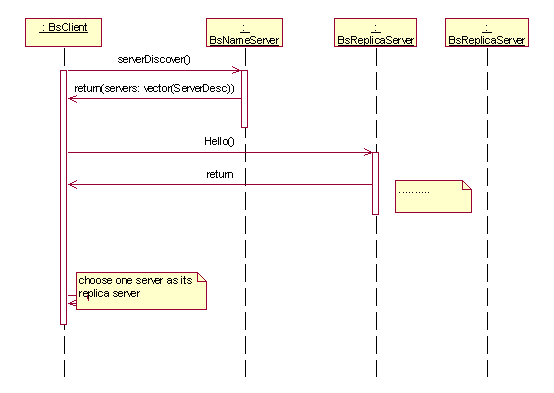
The information for the file servers in the system is kept by the name
server. The client keeps the access information of the name server in
the system. When a client intended to connected to the system and access
the files in it, first it need to contact the name server. From the
name server, it gets the access information of file servers and chooses
the one closest to itself to connect. Once the client connects to a
file server, it uses it as its cache server and gets the access to the
files in the whole system.
In the discovery process, after getting the file servers’ information,
the client contacts the servers simultaneously in multi-thread to find
out the simple response time of each server and select the one with
least response time. In this way, the time discovery process takes decreases.
The mechanism is shown briefly in following diagram.
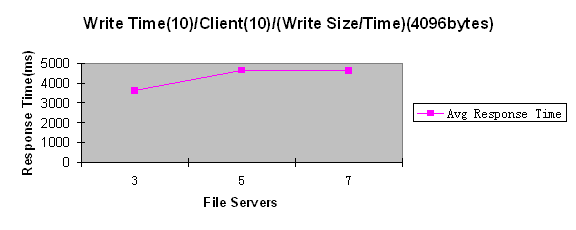
Load Balance
In this implementation, due to the short of time, objective of load
balance is implemented partly. The part of the file process balance
on primary servers given in the design phase was not implemented in
our first version of Blue Source. The implemented parts are:
The file management load balance - File Management
load balance:
Distribute the files in the system in order to have the file manage
burden share in the whole system well. The way in which the system achieves
this is to create file on appropriate file servers, including the file’s
primary server and backup server, according to servers’ current
load.
The replica server’s load balance –
finding the replica server with shortest response time.
When the client connects to the system, it finds the server with the
shortest response time to its contact. In this way, 2 goals are achieved:
a). the client finds the nearest replica server to it among all the
replica server. Thus it gets a better response time when access the
files in the system.
b). the work load of replica servers is well distributed among the replica
servers in the system, because the response time of a replica server
partially reflects the work load of it. Thus by assigning the replica
server with shorter response time to a client, the client request process
load is assigned to a replica server with less work load.
System Scalability
With the load balance of Blue Source, the system of Blue Source can
scale with the number of servers and the number of clients. When client’s
number increases, the work load is shared among the replica servers;
when the number of servers in the system increase, the new server with
less file or with less requests will be more likely to be assigned new
files and new tasks. In this way, the system tries to work smoothly
and improve the utility of the system with the change of the number
of servers and client.
File Consistency
Both in the pessimistic scheme and the optimistic scheme, one of the
ideas is the same: centralized control of file access – all accesses
to the file that can modify the data in the file should go through the
primary server of the file. There are 3 issues in the file consistency:
Updating modified data to clients and replicas.
When a file is modified through the primary server of the file, the
primary server will inform all replica servers that opened the file
to update the modified data in the file; in turn the replica server
will inform the client to update the corresponding file data. In this
way, the client’s read can get the update data in a file, no matter
who modified the file.
In order to improve the performance of updating file, all the update
is performed parallel with multiple threads. Each replica and client’s
file copy is updated simultaneously by individual thread.
Update modified data to the file’s consistent
copies (primary copy and backup copy):
The primary server of the file will update backup copies of the file
after updating its own copy of the file, by sending update requests
to these servers. In this update process, from the update of the copy
in the primary server until the update-completed message from all other
servers for the file are received by primary server, no other operation
request on this file in the request queue would be performed.
File merge
In pessimistic scheme, there can only be one client access a file at
a time, so there is no file merge problem. In optimistic scheme, there
can be more than one client simultaneously access the same file with
read-write mode. So, the primary server needs the capability to merge
or resolve the different modification to a file.
File merge in Blue Source is done in following way:
For a new modification coming, if the new modification is file is consistent
with the passed modifications (that is they modified different parts
of the file, whose sections are not overlapped), then merge the new
modified file with the old one (that is apply all the changes to the
file and save it). If there is confliction between the new modification
and the old ones (that is the sections of the file they modified are
overlapped), the newest modification is submitted to the file
File availability and Fault
tolerance
• Fault tolerance in Blue Source manages deals with the failure
of primary file server and the failure of replica file server. The disconnection
management handles the disconnection between the client and replica
server and the disconnection between the replica server and primary
server.
When the disconnection between the replica server and client occurs,
the client try to find a new replica server to connect to the system.
If the disconnection occurs in some access to a opened or opening file,
a new file replica is created on the new replica server.
If the primary file server failed when or after a file is opened for
a client, the cache server, which is trying to contact it, will contact
the name server, and the primary server will be dynamically assigned
to a previous backup server and the access of the file will be directed
to the new primary file server. The failure of the former primary file
server and the file update information will be recorded by the name
server.
• Access control
Every file manipulation operation has user account information attached
to it. Before apply the operations, the primary server will check the
account information in the request and check ACL information to give
out the permission.
File Operations
The basic idea of Blue Source’s file operation is: centralized
access control and distributed work load.
On one hand, the file operations, like multiple file update, are controlled
and scheduled by the file’s single primary server. It’s
the primary server’s responsibility to implement the multi-exclusive
access and keep the consistency among copies of a file. Every operation
on a file should be permitted and controlled by the file’s primary
server.
On the other hand, the file operation load is distributed. This is implemented
in 2 ways: load balancing between the servers that keep a file’s
copies and dynamic primary server. While the control to access of a
file is centralized to the primary file server, the load of file operation
and transfer can be burdened by all the servers that hold consistent
copies of a file. And if a file’s current primary server has a
heavy work load and the file is not opened on the primary server, then
the file’s primary server can change to another server(previously
backup server) when the next open request comes
File open
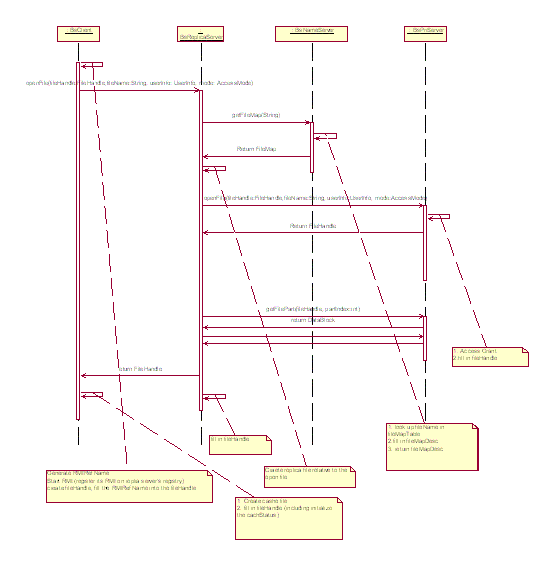
The cache server contacts the name server to obtain the location and
information of the file. Then the cache server according to user’s
request and user identification information make file open request to
the primary server local replica for the file. The primary server of
the file checks the user’s acl information and permits or denies
the request. If the request is permitted, an access session descriptor
and a file handle are created. In Basic version of the project, the
open time of the file and lease period are set into the session descriptor.
Then the file handle is return to the cache server, and the cache server
establishes a local replica of the file, put information related to
the cache server into the file handle and transfer the file handle to
the client as the return variable of open request.
File read
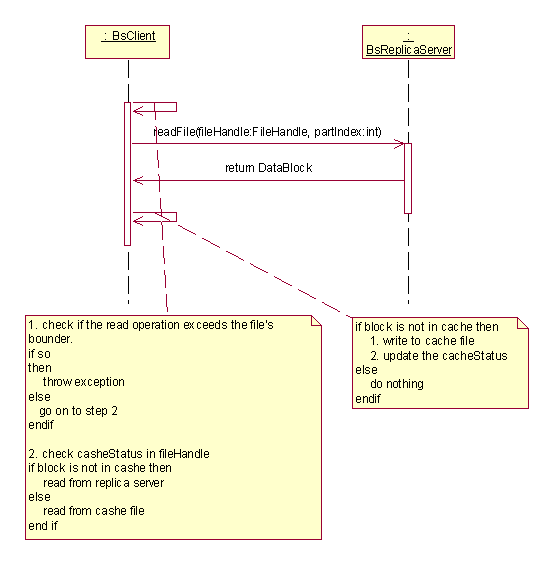
If the part of the file is in the client’s cache, the data is
read from the client cache; otherwise, the client sends the read request
to the cache server, and the cache server returns next block of data
to the client.
File write
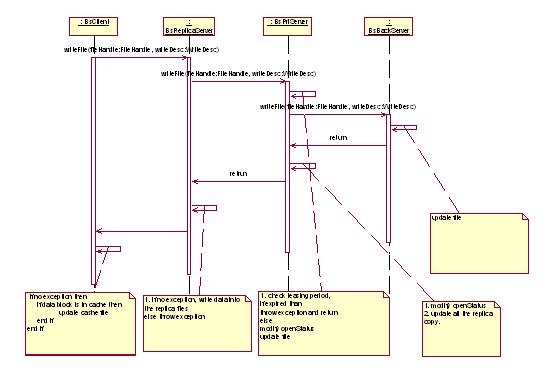
Update the modification client made to the file. This is done by first
updating the file in cache server with the modification the client performed
in its own cache and then updating the copy of the file in the primary
server with the replica in cache server. The file update message contains
the write log which has a description of the write operation. When the
file is updated in primary server, confliction check, file merging(if
necessary) and file update consistency mechanism are performed.
File merging: Check if the modifications to the file in 2 requests have
overlap section. If they are, there is confliction, the latest one is
chosen to update the file; otherwise merge the two update.
In the basic version, when a file write request exceed the lease period,
the file would not be updated as requested.
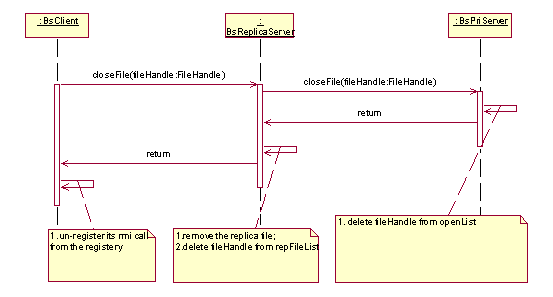
File close
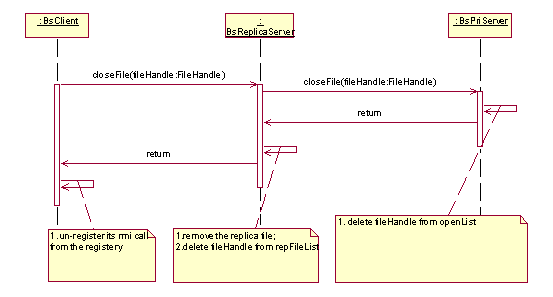
Update the modification client made to the file first. Then remove information
for the opened file in the system, including file handle, entries in
the opened file list on primary file server and cache server.
File creating
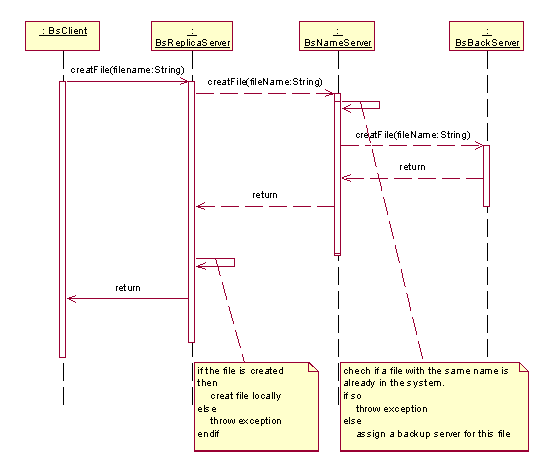
Create a file on the server the client currently connected to and set
it as the primary server. Make copies of the file on the file’s
backup servers. Register the file and its server on the name server.
File delete
The cache server pass client’s delete request to the primary server
of the file. The primary server checks if there is any handle for the
file on the primary server’s opened file list, that is to check
if the file is opened for any client. If it is, the delete request is
denied. If it is not, delete all the copies of the file in the system
and remove the record for the file on the name server.
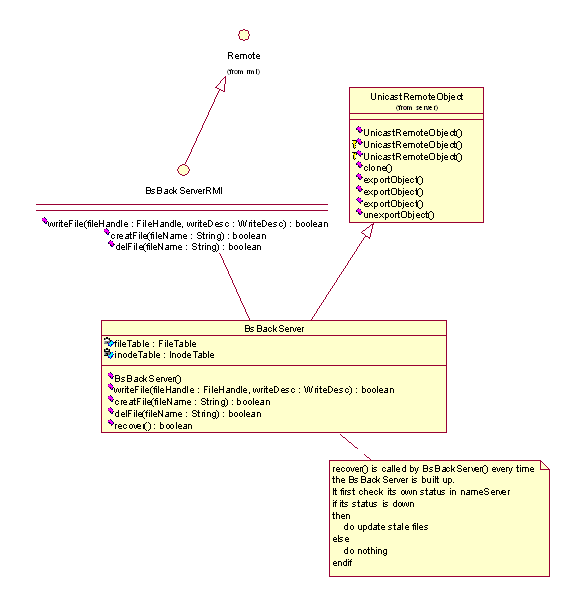
Implementation
Primary Server