| |
 |
|
HOME > Course
Projects > Artificial Intelligence > Empire
Builder Game Agent
Requirement
AI Methods Used
...Heuristic Search
...HTN planning
...Learning
Main Algorithms
Challenges & Future Work
Download the codes from HERE
Requirement
In this project, we need to build an agent who acts as a game player
to play a simplified Empire Builder Game. The map used is a hex map, which
is simpler than the original one in the real game. The board is from (0,0)
to (21,59).
AI Methods Used
Heuristic Search
We are using a revised version of A* search in this project. Generally,
A* search can search a least cost path between two points. However, if
we use such kind of search in our project, we will meet some problems.
Problems
1. Normally, agent finds an optimal way to build from A to B, delivery
goods to B, then finds an optimal way to build again and pick up the goods
from C. It is quite stupid for the agent to work like this. At least,
the agent can choose a point as reference to search the optimal path.
By considering the point C, agent can find a more proper path to build
from A to B. Even if the path from A to B is not an optimal one, it is
a better path for us to build between three points. The first change we
made is to introduce another point, which is in the next step of the current
plan, as a reference to search and find the path.
2) It is quite stupid for the agent to build a brand new path from A
to B. And because some part of the path has been build before, the agent
no longer needs to pay for building this part of path. To utilize what
has been built before is what we need to change. For this reason, we define
a new list to what we have built. The points on these paths are points
we can build from. The path costs of each step in these paths are set
to zero. When the agent wants to build from A to B, it will try to end
to the points that railways have been built on rather than simply building
from A directly to B. In searching, all that has been built will cost
zero, rather than the real cost agent needs to pay. It is clear that the
path the agent finds finally will no longer the optimal one.
3) In the game, there is more than one agent, what will happen is that
others will build the path. If this is happened before the search begins,
it is not so difficult to solve. In the search, we mark this kind of paths
and set their costs to infinite large. Thus all these paths will never
appear in the whole search procedure
Heuristic Functions
Some admissible functions (such as functions based on straight-line distance
or other distance) will help agent to find an optimal path. But they are
not fast enough. Others are not as good as these functions, but they are
faster. We have tested several functions, typically, below are some fast
and useful functions.
1) distance / (sqrt 2) not admissible
2) |x1-x2| + |y1-Y2| not admissible
3) |x1-x2| + |y1-Y2|/2 admissible
HTN planning
In project, use HTN planning as a kind of technology for our project mainly
because in the high level, it is quite clear what the agent need to do
in order to reach the goal.
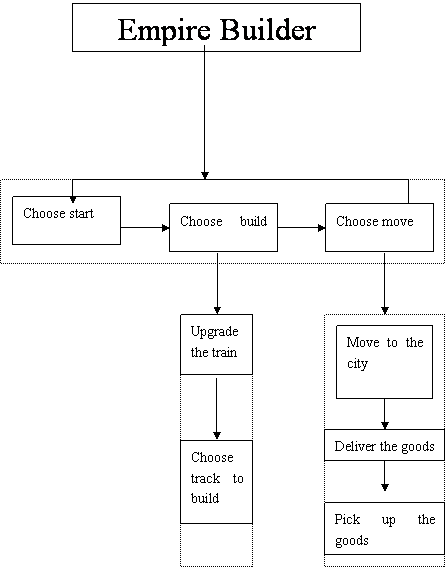
It is just a very simple graph of Empire Builder. Actually,
the agent needs to deal with the result returned from the server after
sending its actions.
The three actions in the first level
1) Choose to start: choose a city to start.
2) Choose to build: choose tracks to build
3) Choose to move: choose the place to move, deliver or pick up goods.
Choose to build can be decomposed into:
1) Upgrade the train
2) Choose track to build
Choose to start can be decomposed into:
1) Move to the city
2) Deliver the goods
3) Pick up the goods.
Learning
IThey are mainly two parts that adding learning technologies into the
system.
Heuristic Search
Heuristic functions are very important to heuristic search. Some
are quite good, admissible and can find optimal solutions. Others are
not so complicated, not so good, only can find good solutions in most
situations. But they are quicker. In an interactive game, both the good
solution (track to be built and move) and the search speed are important.
In the first part of the Empire Builder game, there are very few railways
in the map, to find and build optimal railways are important. When most
of the railways are large part of them are built by others, it is not
so easy to search and find an optimal road. To find a good road to build
is much more important than find an optimal one.
We add learning technologies to the heuristic search so that the heuristic
search can choose different heuristic functions at different situation.
Choose the city to move
When the agent moves to a city, it will deliver or pick up goods
or does both of the actions. In the program, how to choose the city to
move is based on three demand cards. To choose goods from a demand card
based on different elements. At the beginning, because the railways are
not built too much, it is good to choose a city very near. Therefore,
agent can deliver and pick up goods very quickly, and then can earn money
quickly. But after some turns passes, to choose good in the demand card
so that the agent can get larger profit becomes more important, because
the train has been upgraded and the railway are built. Adding learning
skills in city selection help agent to choose different cities under different
situations.
Main Algorithms
Choose goods from demand card
In order to choose a reasonable goods from a demand card to delivery,
the program will according the current player position to use the hfvalue
(amount, hf3cities(pick-up-city, delivery-city, current)) to determinate
which city is the best pick-up-city for this good in the demand, then
selected the best demand in the card.
Choose the demand card
If the train does not upgrade, the load in the train is 1, so we only
need to select the best card according to the hfcard in the cards, and
push it to the planning cards. If the train has upgraded, the load of
the train is 3, we can push all 3 cards to the planning cards.
Heuristic search
It is like the general A* search, the most different parts are:
1. if the track is occupied by myself, the a* will regard the cost of
the track as 0
2. if the track is occupied by myself, the a* will regard the cost of
the track as + infinite.
3. can according the current planning to select the path from source to
target.
4. can adapt the city-limit-p
4.When searching, begins from one point that in the railway one has built
than directly from the beginning point.
First plan
Due to the goods on the card the agent chooses as the first card and other
goods on the other two cards, find appropriate pick up point. Introduce
all these points into the planning. The result has three parts, one for
the first point to pick up or deliver some goods, the other two are for
other demand cards, and the actions in the second part should be executed
before the actions in the third part. Generate the list to build and move.
Choose start
Based on the card selected as the first card, choose a pick up place as
start place
Re-planning
When agent delivers one goods, then call this function to re-planning.
The procedure is similar to the first planning. Because now it has a new
card, the whole planning needs to be rescheduled. Some part will become
the first part of the planning, which will be executed the next turn..
Others may upgrade from the third part to the second part.
Choose build
First check to upgrade the train. Then build the list generated by the
planning. Each time the node build one path, then waiting for the Process
Result function to process the result and then continue to build until
it cannot build any more or the list is nil.
Choose move
Move along the list generated by the planning. Continue to move until
it reaches the move limited or the move list is null. For the next situation,
the agent will then execute the actions attached by that point, deliver
or pick up good or both. Then re-planning.
Process Result
This function processes all the results returned from the server.
Challenges & Future Work
Heuristic function
It is very important to find a good heuristic function. But on the other
hand, it is not so easy to find a good heuristic function that works not
only good but also quick.
Using other’s information
This is a big part that can continue to do some work on it. Now consider
only when a track is already built by other player, the agent can then
call the heuristic function to re-search. And we add code into the heuristic
search function to help search.
Forward building and re-planning
If a kind of goods in a demand card has been delivered, the agent will
get a new card. Then the agent needs to re-plan its existents planning.
It is clear that the program can plan the whole six cities and six activities
at the beginning. But the agent will only build the track to the first
deliver place. Because when the new card comes ,the agent will re-plan
the rest part of the planning and add more activities into the plan, it
is not a good way to build some track into a no use city.
This means to build the tracks after the first deliver city is not so
easy to decide. We tried to build some extra tracks before re-planning
happens, but we still did not reach a good evaluation that what is worth
building.
On the other side, the re-planning is not so easy to do. It is one of
the hardest parts of the project. One thing is that we need to utilize
the existent planning. Another thing is we should merge activities if
they are in the same city. It is not necessary for an agent to go to a
city twice in a plan.
Interrupt others
A good agent should not only do its own work. It should also interrupt
others in such an open and competitive environment.
This is a part that we can do if we have more time. Unlike to use the
other’s information to help the agent’s own decisions, the
agent will use what it get to interrupt others and let others cannot work
well. It is difficult but interesting.
Utilizing the specific information of the
map
To learn and utilize the specific information is a work we planed to do
but actually did nothing. Because each map has its own specific information,
we may have some ways to utilize such kind of information
|

