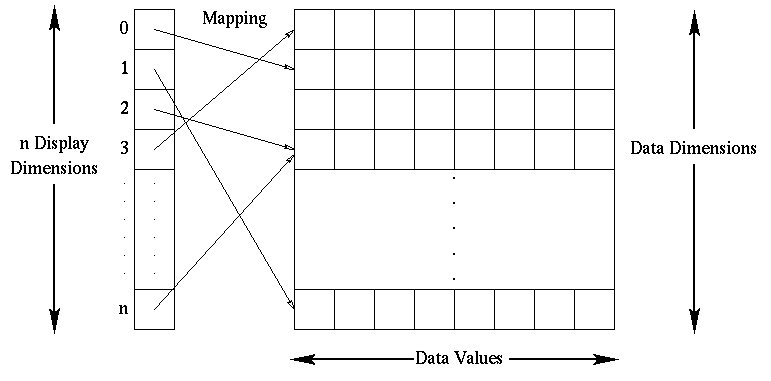
here is a diagram that shows how to visualize the data structure:
//
// DataSet.H
//
// This file defines the main DataSet class that describes a single entry
// in our top level data structure.
//
// Ted Bedwell and Jim Kukla Jan. 1998
//
// $Id: DataSet.H,v 1.9 1998/03/30 13:47:59 jkukla1 Exp $
#ifndef SFA_DATASET_H
#define SFA_DATASET_H 1
#include "String.H"
#include "MappingNode.H"
#include "PackedGlyph.H"
class DataSetList;
class String;
class DataSet
{
private:
//Static class variables
static long next_id;
static int num_maps;
// Data Set label and unique ID
long set_id;
String set_label;
//Number of Data Dimensions and their length
int num_dimen;
int dimen_length;
int num_tsteps;
// Some internal run-time state variables: the current time step
// and whether or not this data set is currently within view.
int current_tstep;
int visible;
//Data Dimensions
double ***dimen;
// Max and min values of each dimension
struct Maxmin {double max, min; } *dimen_maxmin;
//Array of Data Dimension Labels
String *dimen_labels;
//Display Dimension Mappings
double **maps;
MappingNode ** mappings;
// An array of translated copies of each data dimension.
// These are generated on-demand for each time step when
// a request to view that time step arrives. At that point,
// the view is cached. The theory is that most data sets are
// static and so we can avoid re-translating data dimensions
// quite often. A dirty flag is associated with each data set
// in hopes that data sets will either be very dynamic or totally
// static. If this granularity proves inadequate, future revisions
// may use a flag per time step. Hopefully this will not be
// needed.
PackedGlyph ** cooked_data;
char cooked_data_dirty;
// Labels for each of the display dimensions.
static String display_dimension_labels[] ;
// A list of the currently defined mapping functions.
static MappingFunction mapping_function_table[];
public:
//Constructor
DataSet(const String & label, int dimensions, int length, int tstep);
//Destructor
~DataSet();
//Insert a data dimension
void setDimension(int tstep, int index, double *&data, String label);
//Set and Unset a dimension label
void setDimenLabel(int index, const String & label);
void unsetDimenLabel(int index);
// Set and Get dimension min max values
void setDimenMaxmin(int index, double mx, double mn);
double getDimenMax(int index);
double getDimenMin(int index);
//Set data set Label in case it needs to change
void setSetLabel(String & label);
//Set and unset a mapping
void setMap(int map_index, int dimen_index);
void unsetMap(int map_index);
// Accessor to get the set id
int getID() {return set_id;}
// Accessor that returns the number of time steps in the data set
int getTsteps() const {return num_tsteps;}
// Mutator that tries to set the new time step to tstep and
// returns the new time step if successful, the old one if not.
//
// To check for errors, use something like:
// if (ts != ds.setCurrentTstep(ts))
// cerr << "Time Step unchanged. Error.\n";
int setCurrentTstep(int tstep);
// Accessor that returns the current time step in the data set
int getCurrentTstep() const { return current_tstep; }
// Accessor to get the set label
String getLabel() {return set_label;}
// Method that performs the translation from raw data to the
// display-ready cooked format.
int translate(void);
// Method to read in a set file named filename from disk and
// initialize all the appropriate data members of the instance.
int readFile(String filename);
//Print test routine
void print() const;
friend int main(int, char **);
};
#endif
//Constructor
Note that these are not necessarily values in the data set, but represent a theoretical min-max pair. This can be used for cases where the possible range of values is very great, but the actual values all fall within a close range. This helps avoid perceptual misunderstandings about mappings where a relatively closely grouped set of values appear as a very wide range of display values.
To check for errors, use something like:
if (ts != ds.setCurrentTstep(ts)) cerr << "Time Step unchanged. Error.\n";
There is currently no error checking for this function.
There is currently no error checking for this function.
During a single run of SFA two data sets are guaranteed not to have the same ID.