| UMBC CMSC 491/691-I Fall 2002 |
[
Home
|
News
|
Syllabus
|
Project
]
Last updated: 11 September 2002 |
The answers to the questions will depend on how you segment the text into words. I preprocessed the text using NSGMLS, a simple SGML parsing tool, to output text and tags in a normalized, easy-to-parse format. After this, I converted non-alphanumeric characters to whitespace, and normalized the text to lower case. For some questions (it's clear which ones from the code) I excluded numbers from the counts.
This can be answered with the following pipeline:
nsgmls -E0 reut2-*sgm | \ # Use NSGMLS to parse SGML out
grep '^-' | \ # and take only PCDATA lines
perl -ne 's/^-//; # cut leading - from NSGMLS
s/\\n/ /g; # Fix NSGMLS escaped newlines
s/&[a-z]+;/ /g; # Remove SGML entities
s/[^[:alnum:]]/ /g; # convert punct -> space
tr/A-Z/a-z/; # normalize to lower case
print join("\n", split), "\n";' | \ # print 1 word/line
sort | \ # sort the words
uniq | \ # remove duplicate lines
wc -l # count the number of lines
Try out the pipe, adding one stage at a time, to understand
how it works. The 'perl' options '-ne' mean to repeat the
commands in quotes on each line. The first three Perl
transformations are to deal with NSGMLS output. According
to this pipe, there are 55,377 unique words
in Reuters-21578.
Note, if you modify the pipeline above by inserting the
following before the 'sort':
grep -v '^[0-9][0-9]*$' |to remove numbers, there are only 45,741 unique words.
This can be answered by counting the REUTERS tags:
cat reut2-*sgm | grep '<REUTERS' | wc -l
This question could have also been answered by reading the
documentation, or even by making a clever guess based on
the collection title: there are 21,578 documents. (The
collection is so named to distinguish it from earlier
versions that had a different number of documents.)
There are a lot of ways to answer this one. With a smaller collection, I might have used a Perl incantation to dump each document into a separate file:
cat reut2-*sgm | \
perl -ne 'if (/<REUTERS.*NEWID=\"([0-9]+)\"/) { # set output to
close OUT; open OUT, ">$1"; # NEWID content
}
# ...
# rest of Perl normalization mishmash
# ...
print OUT join("\n", split), "\n";' # print 1 word/line
Then, I could use 'wc -l' to count the number of lines (in our
case, each line is a word) in each file, and then use 'sort
-n', 'head' and 'tail' to get the lists. This collection
would make 21,578 files in my directory, which might get a
little unwieldy. Instead, I used the following Perl script:
NOTE: This script had a bug when I showed it initially in class. It counted characters in the document, not numbers. Reasonable for a length measure, but not when the question asked for the number of words!
#!/usr/bin/perl
#
# Usage: ./reutcount.pl reut0*.sgm
#
use strict;
my $docid = -1;
my @doc;
@ARGV = map { /\.sgm$/ ? "nsgmls -E0 $_ 2>/dev/null |" : $_ } @ARGV;
LINE: while (<>) {
if (/^ANEWID/) { # new document (and ID)
chomp;
my (undef, undef, $newid) = split; # get NEWID
$docid = $newid;
@doc = ();
next LINE;
}
if (/^-/) { # text in a doc
s/^-//; # Remove leading hyphen
s/\\n/ /g; # Fix NSGMLS newlines
s/&[a-z]+;//g; # Remove SGML escapes
s/[^[:alnum:]]/ /g; # Convert non-alphanumerics to spaces
my $line = lc; # Normalize to lower case
push @doc, split ' ', $line;
next LINE;
}
if (/^\)REUTERS/) { # End of a doc... do counting
print "$docid\t" . scalar(@doc) . "\n";
@doc = ();
next LINE;
}
}
With the following results:
| Length (docid) | |
|---|---|
| Top 10 | Bottom 10 |
| 2429 (doc 15875) | 32 (doc 10033) |
| 2299 (doc 15871) | 32 (doc 12234) |
| 1391 (doc 11224) | 32 (doc 13746) |
| 1120 (doc 6657) | 32 (doc 19354) |
| 1089 (doc 5214) | 32 (doc 1969) |
| 1085 (doc 17396) | 32 (doc 636) |
| 1079 (doc 5985) | 32 (doc 7025) |
| 1052 (doc 17474) | 31 (doc 12455) |
| 1051 (doc 17953) | 31 (doc 18639) |
| 1051 (doc 7135) | 9 (doc 12793) |
Modify the pipeline from question 1 (excluding numbers), by changing 'uniq' to 'uniq -c' (prints the number of duplicates with each line), and replace 'wc -l' (which simply counts the number of lines) with 'sort -n | tail -10' with sorts the lines numerically and prints the last 10 lines:
26979 mln
27621 for
35275 s
53153 a
53276 said
55098 and
55635 in
74262 of
74937 to
144803 the
Another couple pipe tweaks:
nsgmls -E0 reut2-*sgm | \
grep '^-' | \
perl -ne 's/^-//;
s/\\n/ /g;
s/&[a-z]+;/ /g;
s/[^[:alnum:]]/ /g;
tr/A-Z/a-z/;
print join("\n", split), "\n";' | \
grep -v '^[0-9][a-z0-9]*$' | \ # Reuters has some strange numbers
sort | \
uniq -c | \ # print counts of duplicate lines
sort -n | \ # sort numerically
awk '$1 >= 10 {print}' | \ # print lines where "field 1" (the count) is greater than 10
head -10 # print the first 10 lines
It turns out that there are a lot of words that occur 10 times.
(How many?) My pipe above lists them alphabetically, so I get:
10 abnormal
10 abrupt
10 accomplish
10 achievements
10 acknowledging
10 acp
10 acqu
10 acquir
10 admitting
10 adv
You get the idea... I count 15,010. Here's my pipeline:
nsgmls -E0 reut2-*sgm | \
grep '^-' | \
perl -ne 's/^-//;
s/\\n/ /g;
s/&[a-z]+;/ /g;
s/[^[:alnum:]]/ /g;
tr/A-Z/a-z/;
print join("\n", split), "\n";' | \
grep -v '^[0-9][a-z0-9]*$' | \
sort | \
uniq -c | \ # print counts of duplicate lines
awk '$1 == 1 {print}' | \ # print lines where "field 1" (the count) is 1
wc -l # count the number of lines
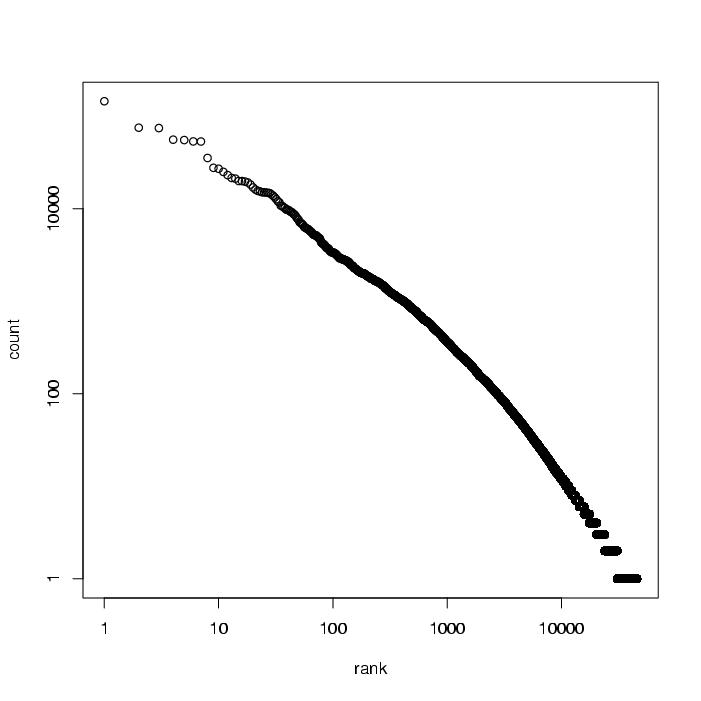
For the graph, I used a pipeline similar to question 4 to output a set of graph coordinates:
nsgmls -E0 reut2-*sgm | \
grep '^-' | \
perl -ne 's/^-//;
s/\\n/ /g;
s/&[a-z]+;/ /g;
s/[^[:alnum:]]/ /g;
tr/A-Z/a-z/;
print join("\n", split), "\n";' | \
grep -v '^[0-9][a-z0-9]*$' | \
sort | \
uniq -c | \ # print counts of duplicate lines
sort -nr | \ # sort numerically, in reverse order
awk '{print $1}' | \ # print the count only
nl # preface each line with a line number
# which will be the X coordinate
The graph [Postscript] was generated using R, a free statistical package similar to S-PLUS (see for more details).