We think of a linked list as this:
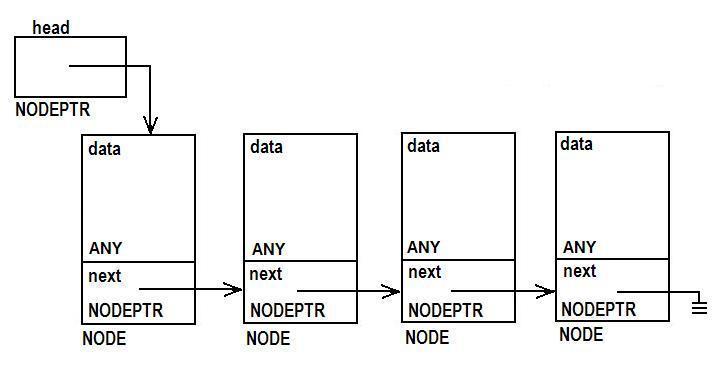
The data section of the nodes can be as simple as a single int, or as complex as an entire struct. The head pointer allows you to access the first node in the linked list to perform various operations on the list.
Here are the definitions found in the linkedlist.h file and a picture of the node that we'll be using in the lab today. It's similar to nodes you may have seen in lecture.
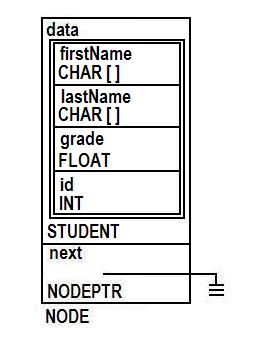
#define NAMESIZE 20
typedef struct node * NODEPTR;
typedef struct student
{
char firstName[NAMESIZE];
char lastName[NAMESIZE];
int grade;
int id;
} STUDENT;
typedef struct node
{
STUDENT data;
NODEPTR next; /* OR struct node *next; */
}NODE;
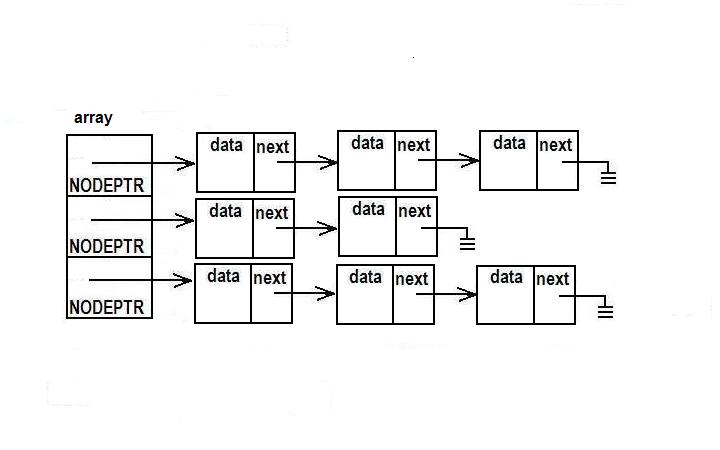
If we have a lot of data, which is all of the same type, that we'd like to organize into groups, we can choose to make a separate linked list for each group. When there are a lot of groups, rather than giving each group a unique variable name, it makes sense to use an array of node pointers, where each element of the array will contain the head of one of the lists. If we #define the names of the groups and use them as indexes into the array, our code be quite readable and meaningful.
Now you are ready to begin the lab. Go to Step 0